Abstract
The YOLO (You Only Look Once) series of algorithms has revolutionized the field of real-time object detection. This report provides an in-depth analysis of the technical evolution of the YOLO series from v1 to the latest YOLO26 (released January 2026) and the research preview v13. Through architectural innovations, YOLO has achieved a dual leap in accuracy and speed, ultimately entering a new era of end-to-end, NMS-free edge computing in 2026.
1. Introduction: A Paradigm Revolution in Real-time Detection
Traditional object detection was dominated by two-stage methods (e.g., R-CNN series), which incurred significant computational redundancy. In 2016, YOLO recast object detection as a single regression problem, dividing images into grids and directly predicting bounding box coordinates, confidence, and class probabilities. This significantly boosted inference speed and provided a global receptive field. Over the past decade, YOLO has continuously evolved, with YOLO26 now achieving end-to-end detection and optimization for edge devices.
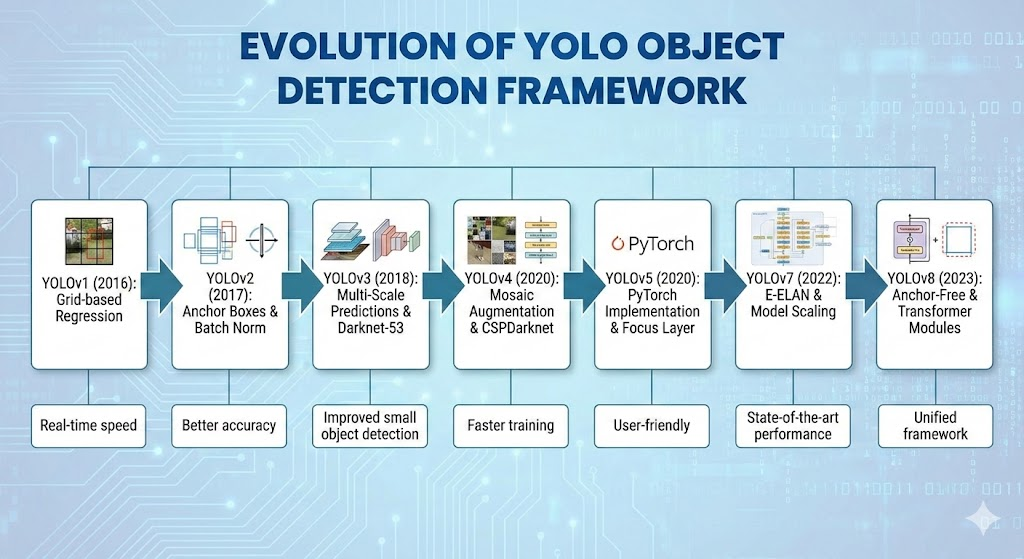
2. Darknet Era: Foundation and Architecture Establishment (YOLOv1 – YOLOv3)
Early YOLO versions were built on the Darknet framework.
2.1 YOLOv1: Grid Regression and Global Inference
- Core Idea: Divides the image into a grid, with each grid responsible for detecting objects whose center falls within it.
- Network Structure and Loss Function: Comprises 24 convolutional layers and 2 fully connected layers, inspired by GoogLeNet. The loss function includes the sum of squared errors for coordinate, confidence, and classification.
- Limitations: Strong spatial constraints, each grid can only predict a few bounding boxes and belong to one class, making dense object detection difficult; poor generalization to objects with unconventional aspect ratios.
2.2 YOLOv2 (YOLO9000): Introduction of Anchor Boxes and WordTree
- Anchor Box Mechanism: Introduced anchor boxes, automatically generated via K-means clustering, to better fit dataset distributions, improving recall and localization accuracy.
- Passthrough Layer: Connects shallow, high-resolution feature maps with deep, low-resolution feature maps to preserve fine-grained spatial information for detecting small objects.
- Joint Training: Constructed a WordTree for large-scale class detection, combining ImageNet and COCO data for joint training.
2.3 YOLOv3: FPN and Multi-scale Prediction as an Industry Standard
- Darknet-53: Adopted a deeper residual network, Darknet-53, as the backbone, using strided convolutions for downsampling to effectively retain feature information.
- Multi-scale Prediction: Borrowed the FPN idea, performing predictions at three different scales (large, medium, small feature maps) to improve robustness for objects of varying sizes.
- Logistic Classifier: Replaced Softmax with independent Logistic classifiers, supporting multi-label classification.
3. Optimization and Tricks Era: Bag of Freebies & Specials (YOLOv4 – YOLOv5)
This period focused on maximizing model performance without increasing inference costs.
3.1 YOLOv4: A Master Integrator of Architectural Fine-tuning
- Bag of Freebies (BoF): Techniques that only increase training cost but not inference time.
- Mosaic Data Augmentation: Stitches four training images into one, enriching backgrounds and effectively increasing batch size.
- CutMix and Label Smoothing: Enhances regularization.
- SAT (Self-Adversarial Training): Improves robustness by adversarial training.
- Bag of Specials (BoS): Modules that slightly increase inference cost but significantly boost accuracy.
- CSPNet: Upgraded to CSPDarknet53, reducing computation and addressing gradient vanishing through channel splitting.
- Mish Activation Function: A smooth, non-monotonic activation function that effectively propagates information.
- PANet and SPP: SPP expands the receptive field, and PANet shortens the distance for low-level localization information to reach higher levels through a bottom-up path.
3.2 YOLOv5: PyTorch Ecosystem and Engineering Implementation
- Native PyTorch Development: Significantly lowered the barrier for developers.
- Focus Layer: (Early versions) Slices and stacks input images, accelerating subsequent convolutions.
- Auto-Anchor: Automatically recalculates optimal anchor box dimensions based on custom dataset annotations before training.
- Scaling Strategy: Introduced n/s/m/l/x models of different sizes, uniformly adjusting depth and width factors for flexible model selection based on hardware capabilities.
4. Architectural Divergence: Specialization and New Paradigms (2021–2023)
YOLO series began to diverge into different technical schools, mainly focusing on Anchor-Free, Reparameterization, and Label Assignment innovations.
4.1 YOLOX: Decoupled Head and Anchor-Free Regression
- Decoupled Head: Decouples classification and regression tasks, using independent branches to improve accuracy and convergence speed.
- Anchor-Free Mechanism: Abandoned anchor-based design, directly predicting distances from grid points to the four sides of the target box, simplifying the model.
- SimOTA: Dynamic Label Assignment: Models label assignment as an optimal transport problem, dynamically determining the number of positive samples, solving sample imbalance and ambiguous sample assignment.
4.2 YOLOv6: Industrial-grade Reparameterization and RepVGG
- RepVGG Architecture: Multi-branch structure during training, fused into a single-path structure during inference, improving hardware parallel computation and reducing memory access.
- SIoU Loss Function: Introduces an angle cost, penalizing angular deviation between predicted and true boxes, accelerating convergence.
4.3 YOLOv7: Gradient Path Design and E-ELAN
- E-ELAN (Extended ELAN): Enhances feature diversity and interaction through “expand, shuffle, merge cardinality” strategy, improving learning capability without solely increasing depth.
- Auxiliary Head and Coarse-to-Fine Guidance: Introduces deep supervision, with auxiliary heads using a “coarse-grained” label assignment and main heads using “fine-grained,” helping to learn more robust features.
5. Unified Framework and Extreme Optimization (YOLOv8 – YOLOv10)
5.1 YOLOv8: The All-rounder Integrator
- C2f Module: Combines ideas from YOLOv5’s C3 and YOLOv7’s ELAN, increasing the number of skip connections and enriching gradient flow while remaining lightweight.
- TaskAlignedAssigner: Assigns a positive sample only when it has both high classification confidence and high localization accuracy, addressing classification-localization misalignment.
- Loss Function: Uses Varifocal Loss (VFL) for classification and CIoU + DFL (Distribution Focal Loss) for regression.
5.2 YOLOv9: Programmable Gradient Information (PGI)
- PGI (Programmable Gradient Information): Introduces an auxiliary reversible branch that generates reliable gradients during training, ensuring deep features retain critical input information. This branch is removed during inference.
- GELAN (Generalized ELAN): A general efficient layer aggregation network that allows flexible combination of various computational blocks, optimizing parameter utilization, and surpassing v8’s accuracy with fewer parameters.
5.3 YOLOv10: End-to-End Breakthrough
- NMS-Free: The core contribution, achieving low-latency end-to-end detection.
- Consistent Dual Assignments: During training, uses both one-to-many and one-to-one heads. The one-to-one head forces each ground truth to match only one prediction box, enabling the network to learn to produce sparse and accurate predictions. During inference, only the one-to-one head is used, completely eliminating the NMS step.
6. Edge-Native Era and Future (YOLO11, v12, YOLO26)
Focus shifted to optimizing actual inference latency for edge devices (CPU/NPU).
6.1 YOLO11: Feature Enhancement and Speed Balance
- C3k2 Module: Uses bottleneck blocks with smaller convolutional kernels, improving computational efficiency.
- C2PSA (Spatial Attention): Introduces spatial attention mechanism after SPPF, enhancing focus on key areas with low computational cost, especially for small object detection in complex backgrounds.
6.2 YOLOv12: Attention-Centric Architecture
- Area Attention: Divides feature maps into areas (horizontal or vertical) for attention computation, controlling computational cost while retaining a large receptive field.
- R-ELAN: Introduced R-ELAN modules with scaled residuals to address training instability caused by attention mechanisms.
6.3 YOLO26: The SOTA Standard of 2026
- Edge First: Design philosophy.
- Native NMS-Free and DFL Removal: A more mature NMS-free architecture, removing DFL, significantly boosting CPU inference speed.
- MuSGD Optimizer: Inspired by LLM training, combines the stability of SGD and the momentum characteristics of Muon, solving the non-convergence issue of NMS-free architectures and shortening training cycles.
- ProgLoss + STAL: Progressive Loss and Self-Training Anchor Loss dynamically adjust penalty weights for small targets, improving small object detection capabilities.
7. In-depth Technical Comparison and Performance Benchmarks
- Performance Benchmarks: YOLO26n achieves a qualitative leap in CPU inference speed while maintaining high accuracy.
- YOLO vs. Transformer (RT-DETR): RT-DETR has high complexity. YOLO26 achieves linear complexity NMS-free detection through CNNs, offering higher energy efficiency on edge devices.
8. Conclusion and Future Outlook
The evolution of YOLO is a history of engineering relentlessly pursuing ultimate efficiency.
- Accuracy: Through multi-scale prediction, PANet, label assignment optimization, and auxiliary supervision, YOLO has thoroughly addressed the early issues of inaccurate localization and missed small objects.
- Speed: Through RepVGG reparameterization, C2f/ELAN lightweight design, and the removal of NMS/DFL post-processing redundancy, YOLO26 has brought real-time detection to low-power CPU devices.
Future Outlook (2027+):
- YOLO-World and Open-Vocabulary Detection: Future YOLO will not be limited to COCO’s 80 classes. YOLO-World, combined with Vision-Language Models (VLM), has achieved zero-shot detection via a “Prompt-then-Detect” paradigm, making YOLO a general visual perception engine.
- Multi-modal Fusion: For autonomous driving and all-weather surveillance, future YOLO (e.g., v13 concept) will more deeply integrate multi-modal data such as LiDAR and thermal imaging, capturing more complex object associations through hypergraph computation.
- Normalization of Neural Architecture Search (NAS): With hardware diversification, NAS techniques for automatically searching optimal sub-structures for specific chips (e.g., Raspberry Pi, Jetson Orin, Hailo) will become standard.
The story of YOLO demonstrates that in deep learning, architectural simplification and deep optimization for hardware often drive technological popularization and implementation more effectively than simply stacking computational power.